Microsoft Word Example Post
When writing a blog post with Microsoft Word – the filename becomes the title. In this case the file name is “2020-01-01-Microsoft-Word-Example-Post.docx”.
There is minimal support for Word documents in fastpages compared to Jupyter notebooks. Some known limitations:
-
alt text in Word documents are not yet supported by fastpages, and will break links to images.
-
You can only specify front matter for Word documents globally. See the README for more details.
For greater control over the content produced from Word documents, you will need to convert Word to markdown files manually. You can follow the steps in this blog post, which walk you through how to use pandoc to do the conversion. Note: If you wish to customize your Word generated blog post in markdown, make sure you delete your Word document from the _word directory so your markdown file doesn’t get overwritten!
If your primary method of writing blog posts is Word documents, and you plan on always manually editing Word generated markdown files, you are probably better off using fast_template instead of fastpages.
The material below is a reproduction of this blog post, and serves as an illustrative example.
Maintaining a healthy open source project can entail a huge amount of toil. Popular projects often have orders of magnitude more users and episodic contributors opening issues and PRs than core maintainers capable of handling these issues.
Consider this graphic prepared by the NumFOCUS foundation showing the number of maintainers for three widely used scientific computing projects:
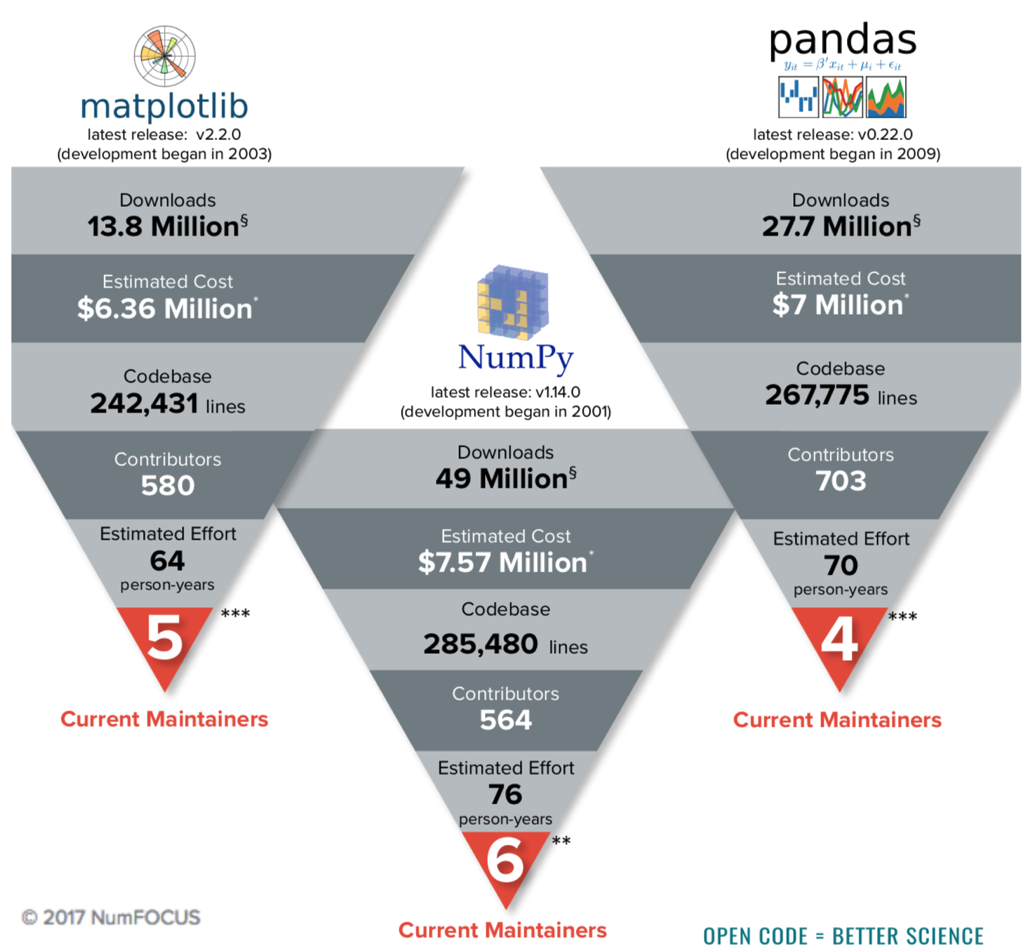
We can see that across these three projects, there is a very low ratio maintainers to users. Fixing this problem is not an easy task and likely requires innovative solutions to address the economics as well as tools.
Due to its recent momentum and popularity, Kubeflow suffers from a similar fate as illustrated by the growth of new issues opened:
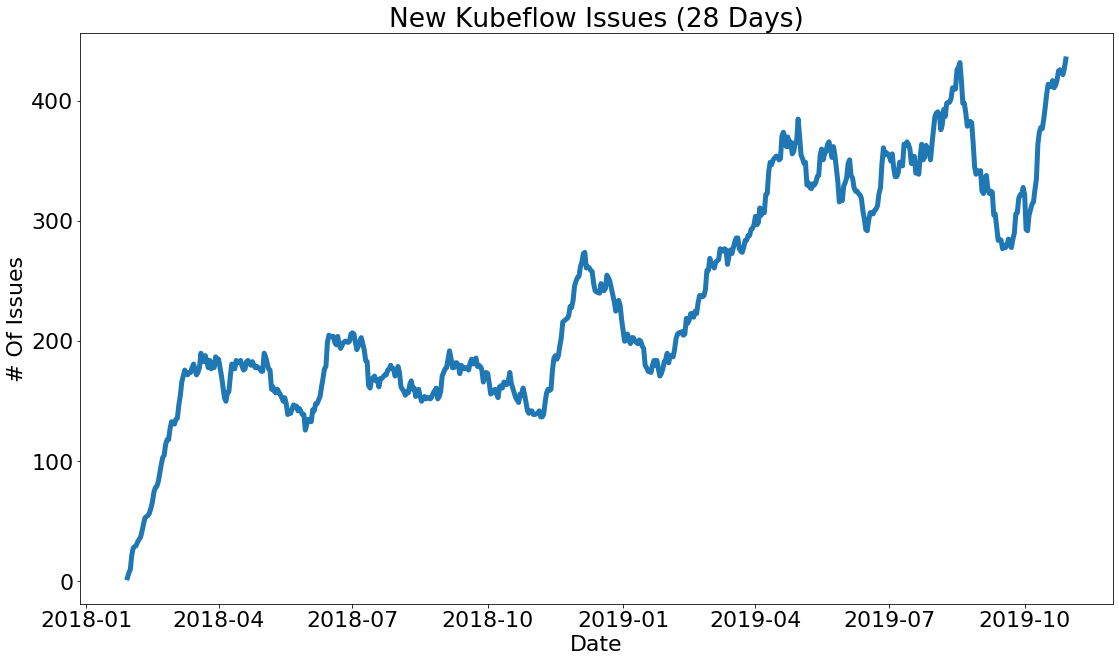
Source: “TensorFlow World 2019, Automating Your Developer Workflow With ML”
Coincidentally, while building out end to end machine learning examples for Kubeflow, we built two examples using publicly available GitHub data: GitHub Issue Summarization and Code Search. While these tutorials were useful for demonstrating components of Kubeflow, we realized that we could take this a step further and build concrete data products that reduce toil for maintainers.
This is why we started the project kubeflow/code-intelligence, with the goals of increasing project velocity and health using data driven tools. Below are two projects we are currently experimenting with :
-
Issue Label Bot: This is a bot that automatically labels GitHub issues using Machine Learning. This bot is a GitHub App that was originally built for Kubeflow but is now also used by several large open source projects. The current version of this bot only applies a very limited set of labels, however we are currently A/B testing new models that allow personalized labels. Here is a blog post discussing this project in more detail.
-
Issue Triage GitHub Action: to compliment the Issue Label Bot, we created a GitHub Action that automatically adds / removes Issues to the Kubeflow project board tracking issues needing triage.
Together these projects allow us to reduce the toil of triaging issues. The GitHub Action makes it much easier for the Kubeflow maintainers to track issues needing triage. With the label bot we have taken the first steps in using ML to replace human intervention. We plan on using features extracted by ML to automate more steps in the triage process to further reduce toil.
Building Solutions with GitHub Actions
One of the premises of Kubeflow is that a barrier to building data driven, ML powered solutions is getting models into production and integrated into a solution. In the case of building models to improve OSS project health, that often means integrating with GitHub where the project is hosted.
We are really excited by GitHub’s newly released feature GitHub Actions because we think it will make integrating ML with GitHub much easier.
For simple scripts, like the issue triage script, GitHub actions make it easy to automate executing the script in response to GitHub events without having to build and host a GitHub app.
To automate adding/removing issues needing triage to a Kanban board we wrote a simple python script that interfaces with GitHub’s GraphQL API to modify issues.
As we continue to iterate on ML Models to further reduce toil, GitHub Actions will make it easy to leverage Kubeflow to put our models into production faster. A number of prebuilt GitHub Actions make it easy to create Kubernetes resources in response to GitHub events. For example, we have created GitHub Actions to launch Argo Workflows. This means once we have a Kubernetes job or workflow to perform inference we can easily integrate the model with GitHub and have the full power of Kubeflow and Kubernetes (eg. GPUs). We expect this will allow us to iterate much faster compared to building and maintaining GitHub Apps.
Call To Action
We have a lot more work to do in order to achieve our goal of reducing the amount of toil involved in maintaining OSS projects. If your interested in helping out here’s a couple of issues to get started:
-
Help us create reports that pull and visualize key performance indicators (KPI). https://github.com/kubeflow/code-intelligence/issues/71
- We have defined our KPI here: issue #19
-
Combine repo specific and non-repo specific label predictions: https://github.com/kubeflow/code-intelligence/issues/70
In addition to the aforementioned issues we welcome contributions for these other issues in our repo.